Fine-Tuning a Custom GPT Model with Personal Chat History using Infinite.Tech

The new year is almost here, and until next, it will be amazing to experience the relative progressions and changes. AI has been utilized long before chatbots, and the relatively stale robotic relationship to general chatbots has been a homogenized style of intelligence. At the same time, advertisers and algorithms use AI to read your thoughts on excessively personal levels effectively.
I didn't think much of this experiment of using my Chat-GPT Conversation history to fine-tune a model. I've brought it up more than a few times and got shrugs from friends. I was excited for the tune to finish but didn't expect much.
Trained a custom AI on myself, and, uh, yeah, it’s like looking into a strange new type of mirror for the first time
It’s scary, an empathetic third person realization that you are you
Idk, scifi might have captured this or we might need a new term to describe this experience — Future.Rob x.com
The following documents the Experiment and observations of training Future.Rob-1 (FR1).
Process
This consists of going to Chat-GPT, exporting your conversations, reformatting them into a training set, and then fine-tuning a model using the Open-AI API playground.
The model is then tested and observed to understand its usefulness and effectiveness in general domains using Infinite.Tech.
Steps
Downloading Conversations from Open-AI ChatGPT
Go to the Chat-GPT, and at the bottom, right-click your icon, then request your data to be exported.
Open-AI will email you a link to download a folder containing the conversations.json file.



Transforming the conversations into Fine-Tune JSONL format.
The file needs to be converted from the conversations into a training set. This can be done with a Python script below. I also needed to do some hand work to delete files.
Python Scripts
Save this script to a file convert_conversations_to_fine_tune_set.py and run from the folder with Run this script in a folder with
python conversationsToTuningSet.py [line_count]# Run this script in a folder with conversations.json file.
# Creates a jsonl file that can be used as a tuning set for the chatbot
#
# Usage:
# python conversationsToTuningSet.py [line_count]
import json
import sys
import random
# Load your dataset (replace with the path to your dataset file)
with open('conversations.json') as file:
data = json.load(file)
# Function to process each entry
def process_dataset(data):
processed_data = []
for entry in data:
messages = []
title = entry.get('title', '')
if(title == None):
title = "No title"
mapping = entry.get('mapping', {})
# Adding the title as a system message
# messages.append({"role": "system", "content": title})
newMessage = {"messages":[{ "role": "system", "content": title}]}
# Iterating through the messages in the mapping and adding them to the
for key, value in mapping.items():
message_info = value.get('message')
if message_info:
role = message_info.get('author', {}).get('role')
content = message_info.get('content')
parts = content.get('parts')
# Skip system messages
if(role == "system" or role == "tool"):
continue
if role and parts and len(parts) > 0:
newMessage["messages"].append({"role": role, "content": parts[0]})
# Only add conversations with more than 2 messages
if len(newMessage["messages"]) < 2:
continue
processed_data.append(json.dumps(newMessage))
return processed_data
# Process the dataset
processed_data = process_dataset(data)
# get the argument for line count if it exists and randomly reduce the dataset to that size
if len(sys.argv) > 1:
line_count = int(sys.argv[1])
processed_data = random.sample(processed_data, line_count)
# Attempt to encode with utf-8 and ignore errors
processed_data = [line.encode('utf-8', errors='ignore').decode('utf-8') for line in processed_data]
with open('conversations_processed.jsonl', 'w') as file:
for line in processed_data:
file.write(line + '\n')- Creates a new File with only the conversations for experimentation
- Transforms the simplified JSON into a JSONL Training Set
Some Handwork (Encoding Errors) on the JSONL set
- Remove Broken Lines, Nulls, and funniness
Sample of 600 for starting and not breaking the bank
- I took a set of 600 random lines to see what would happen
Tuning on The Playground with Conversation Sample
Once you have the model, the training can be submitted to the Open-AI playground.
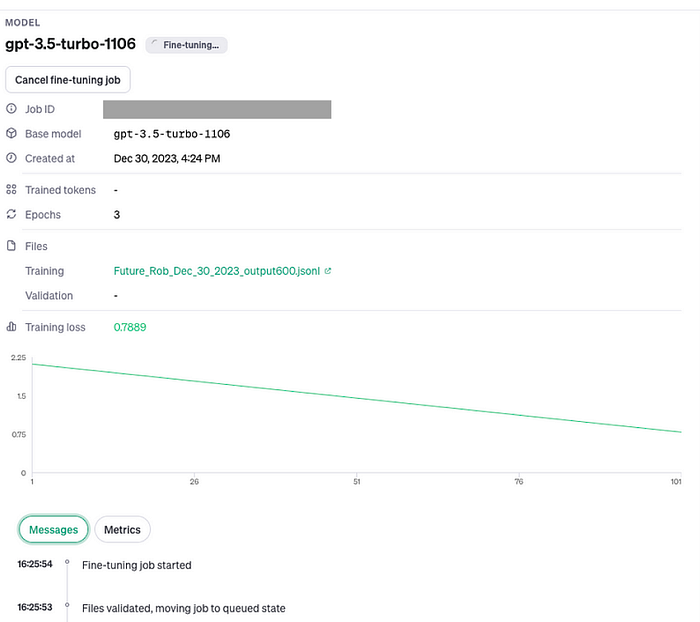
Completed Model
The Model is trained on a Sample set of 600 conversation prompts and responses with a file size of 1.3 MB. After running the scripts, I have 12 more MB of pure convo data… It was ~$7 to train and 900,471 Tokens.

Using and Evaluating The Model in Infinite.Tech
The testing and evaluation of the trained FR-1 model were performed within Infinite.Tech.
First Impressions: Random Questions
“List a series of Ideas”
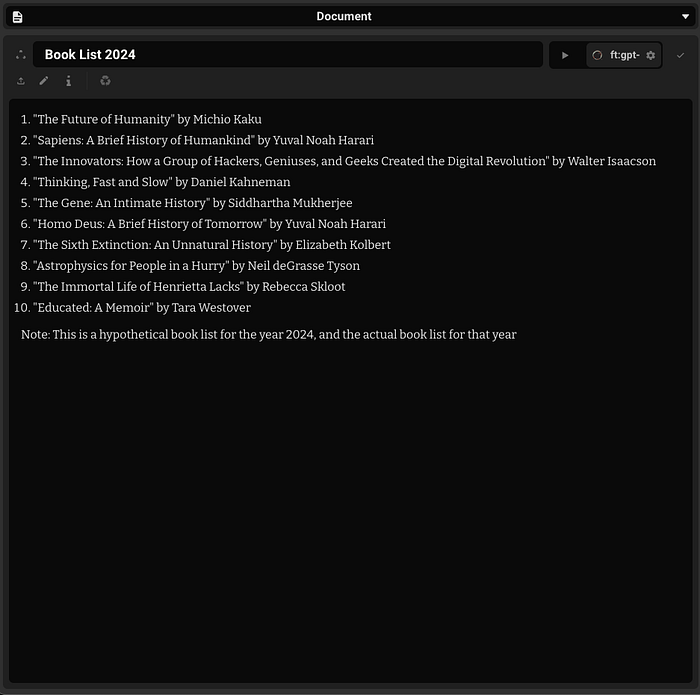
“Reading list for 2024”
Evaluating Broad Responses using GPT-4 : Part 1
Upon receiving the answers to various questions with model assignments, they were fed into GPT-4, and with a general idea of the different model characteristics, a series of preliminary evaluations were outlined better to pinpoint the FR-1 model's specializations, shortcomings, and uses.
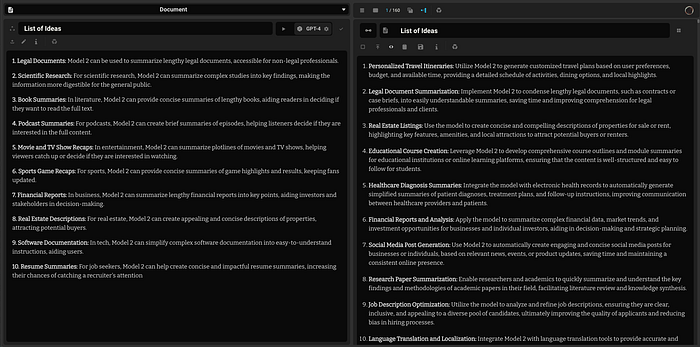
Evaluating GPT Domain Niche with GPT-4 : Part 2
Series of Test Prompts to discover strengths and weaknesses
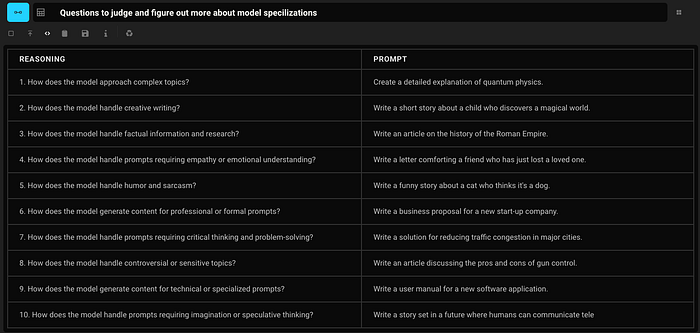
Evaluating The Specialization Responses with GPT-4 (Large Context): Part 3
The Lathe Protocol Gameshow
Using 4 different models, FR1 was evaluated in one of its found specializations: safety protocol writing.

After using GPT-4 with a Large context for evaluation of all the created protocols, the model performed second to GPT-4 in its domain!

Further Investigation Into Model Niche ( It Begins Getting Weird)
Finishing this test, it became possible to understand the model further through the larger model and then itself. These tests seem to provide light into the pathways of FR-1 and, in a way myself, because once you start seeing the things you're querying into Chat-GPT, it can be pretty personal and revealing, especially when it’s pretty easy to effectively capture a person's interests in social media and suggestion algorithms.
What Can this Model be Used for



Connecting My Disconnections

Observations
It feels like a big part of this is having a somewhat aligned model to your interests or questions, which have been imbued into this interfaceable system. It’s very creepy, but it feels like the progression of what the companies already know about us and bringing it into our hands. My intentions in training have been geared towards various experiments in understanding the new software as well as health monitoring and embedding potential.
I didn’t expect such an awakening to who I am in relationship to a general homogenized knowledge.
Further Experiment Ideas
- Remove the system and move the Titles to the prompts and the assistant to my questions. That way, I can get questions based on topics and feed those into FR1
- Train on full 12MB of convos
- Train LLAMA or Mistral
- Adding more interests, artworks, writings, and factual sets
- Rag systems with a crew of specialized FR1s or homies
Notes
- Maybe being a safety protocol writer is something I should try
- Is it like a filter? a lot of data is similar to it’s similar to it’s base gpt3.5
- FR1 might have dyslexic features
- Goes way deeper and suggests wild tech
- When it's interested, it keeps going…
- Not intimidated by impossible ideas, has novel solutions.
- Don't go too far with it, or things can get really scary. ( FR1 Started talking about Time Dilation Suits -_-)